Introduction
Offshore data engineering teams offer real cost and talent advantages — but data engineering is uniquely unforgiving. Unlike a broken feature that a user reports immediately, a degraded pipeline often keeps running while silently producing stale or incorrect data. By the time anyone onshore notices, the damage has already reached executive dashboards and business decisions.
According to dbt Labs' 2025 State of Analytics Engineering Report, 56% of data teams identify data quality as their most critical challenge. For offshore teams managing pipelines across time zones, that challenge compounds fast.
This guide is a practical playbook for US-based mid-market and PE-backed companies looking to build, onboard, and manage offshore data engineering teams that function as genuine strategic assets. It covers team structure, communication cadences, data quality governance, and the operational patterns that separate high-performing offshore teams from ones that quietly erode trust in your data.
Key Takeaways
- Offshore data engineering fails silently: standard software management practices won't catch broken pipelines before they corrupt downstream decisions
- The most common failure point is missing business context, not missing technical skill
- Data quality standards and governance must be documented before the first pipeline is built. Retrofitting is expensive and rarely complete.
- Engineer retention is a data risk: when someone leaves, undocumented pipeline logic leaves with them
- Staff augmentation, dedicated teams, and capability centers suit different stages — pick the model that matches where you are now
Why Offshore Data Engineering Requires a Different Management Approach
The Invisible Failure Problem
A broken software feature gets reported. A broken data pipeline doesn't.
Pipelines continue executing while producing incorrect, incomplete, or stale data — and the problem surfaces only when a business decision goes wrong. Monte Carlo's analysis of 11 million monitored tables found one data quality incident per 10 tables per year, with 15 total hours of data downtime per incident. Pipeline execution faults account for 26.2% of root causes.
In an offshore context, this risk compounds:
- A pipeline that breaks at 2 AM EST may run incorrectly for a full US workday before anyone investigates
- Async communication delays mean a question that takes 30 minutes onshore can take hours to resolve cross-site
- Without clear escalation paths, offshore engineers may lack the authority to act independently — so they wait
The Mindset Shift Required
Managing an offshore data engineering team is less like managing a software feature team and more like managing a distributed data supply chain.
The real performance question isn't throughput — it's whether the pipelines that matter are delivering trustworthy data, on time, every time. That shift in framing changes what you measure, how you structure handoffs, and where you place ownership.
Three things matter most in this model:
- Reliability: pipelines run correctly, not just on schedule
- Escalation clarity: offshore engineers know when and how to act without waiting for US-side approval
- Quality ownership: someone on the offshore team is accountable for data correctness, not just execution
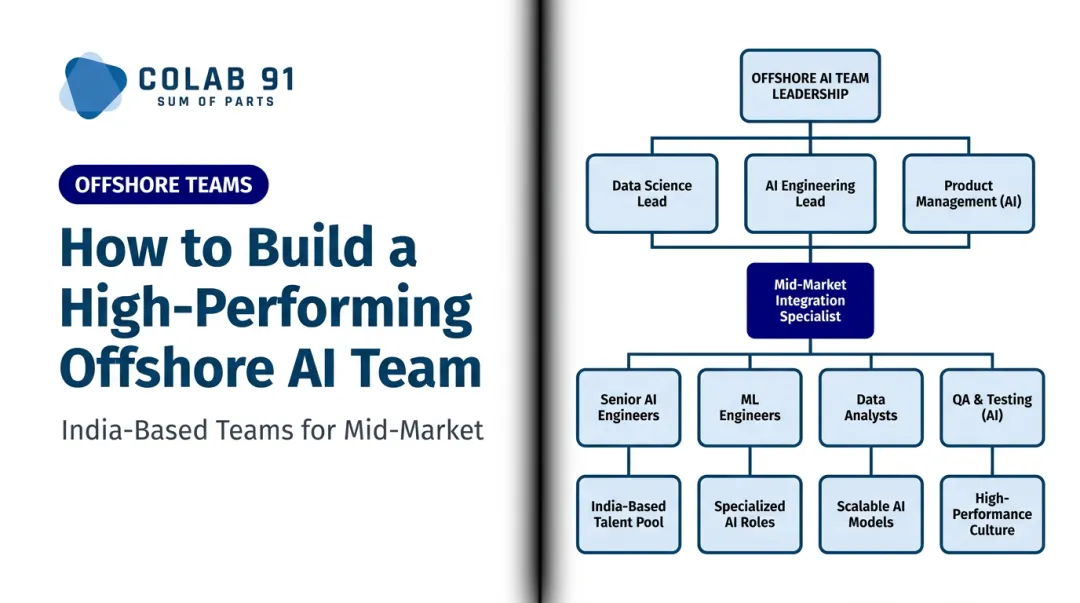
Structuring Your Offshore Data Engineering Team
The Onshore vs. Offshore Ownership Split
Not everything belongs offshore. The most effective split for data engineering keeps strategic control onshore while moving execution offshore:
| Keep Onshore | Move Offshore |
|---|---|
| Data strategy and architecture governance | Pipeline development (ETL/ELT build-out) |
| Stakeholder relationship management | Data quality monitoring and alerting |
| Data contract ownership | Schema documentation |
| Incident escalation authority | Pipeline operations and maintenance |
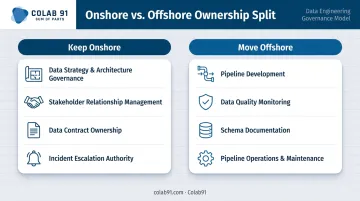
This split respects both cost efficiency and organizational control. Offshore engineers should never be in a position where they're making architecture decisions without context — or waiting for onshore approval to resolve a production incident.
Core Roles to Build Offshore
A functional offshore data engineering team typically includes:
- Data engineers — pipeline build, ETL/ELT development, dbt model ownership
- Data quality analysts — monitoring, threshold alerting, incident triage
- Pipeline operations specialists — scheduling, dependency management, incident response
- Documentation owners — schema docs, runbooks, ADRs
Each role is distinct. Treating data engineers as interchangeable across these functions creates gaps — particularly in quality monitoring and documentation, which offshore teams consistently under-resource.
Choosing the Right Engagement Model
Three models suit different maturity levels and ambitions:
- Staff augmentation — best for short-term or supplementary pipeline work; limited for ongoing data platform development
- Dedicated offshore team — suited to continuous product-line data work with stable scope
- Capability center (GCC) — the right choice for companies building long-term data infrastructure at scale
Colab91's model is oriented toward the capability center approach — building permanent, high-performing India-based teams for mid-market and PE-backed companies, not placing contractors. India hosts 1,800+ GCCs with 2.1 million professionals and $64.6B in revenue as of 2024, and 78%+ of new centers established in 2024 prioritized digital capabilities — reflecting how companies are treating offshore not as arbitrage but as strategic infrastructure.
Phased Scaling and Business Context Onboarding
Don't hand over pipeline ownership too fast. A phased approach works better:
- Months 1–3: High oversight ratio; offshore team reads ADRs, runs existing pipelines, delivers small additions under close review
- Months 3–6: Growing independence on new pipeline components as the team builds a track record
- Month 6+: Offshore owns specific pipeline domains outright, including incident response
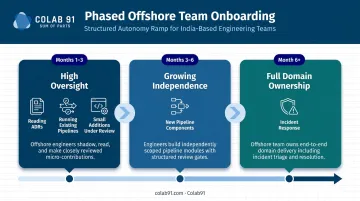
The non-negotiable onboarding component most companies skip: business context. Offshore data engineers need to understand which tables are mission-critical, which pipelines feed executive dashboards, and what downstream consumers depend on each dataset.
Teams without this context make technically valid but strategically wrong decisions — choosing schema structures or transformation logic that looks clean in isolation but breaks reporting for the business.
Communication and Collaboration Architecture
Sync vs. Async: Getting the Split Right
Most information flow should be async. Synchronous time is expensive across time zones — don't waste it on status updates.
Async (default):
- Pipeline status reports and health dashboards
- Code review feedback
- Incident logs and post-mortems
- Documentation updates and schema change notices
Sync (reserved for):
- Schema design reviews and architecture decisions
- Sprint planning and retrospectives
- Data quality review calls
- Production incident response
The 4-Hour Overlap Window
For US-EST and India-IST teams, the usable overlap is roughly 8 AM–12 PM EST (6:30–10:30 PM IST). Schedule sprint ceremonies, architecture reviews, and critical handoffs within this window. Outside it, the team should be able to operate independently — which requires the async infrastructure to actually work.
Define a Communication Charter Before Pipeline Work Begins
This is one practice most teams skip — and always regret. Before any pipeline development starts, document:
- Which channel handles production failure alerts (Slack #alerts, immediate response required)
- Which channel handles architecture questions (async, 4-hour response SLA)
- Which channel handles general development questions (async, next-day acceptable)
- Escalation paths with named owners, not just role titles
- Response SLAs by urgency — a production pipeline failure should trigger immediate escalation regardless of time zone
Without this, offshore engineers default to waiting. That waiting turns into hours of downstream impact.
Adapting Agile for Data Engineering
Clear communication channels set the foundation — but they only matter if the team agrees on what "done" actually means. In data engineering, that definition is more demanding than standard software delivery. A pipeline is done when:
- Tested against real data in staging
- Data quality checks pass and are committed to the CI/CD pipeline
- Schema is documented
- Monitoring and alerting are configured
- Runbook is written for common failure scenarios
- Handoff review is completed with the onshore team

Teams that apply generic software definitions of done to data engineering ship pipelines that work on day one and fail silently on day thirty.
Setting Data Quality, Governance, and Security Standards
Data Quality as Written Contracts
Before offshore work begins, define quality expectations in writing — because ambiguity across time zones becomes broken pipelines:
- Completeness thresholds — what percentage of expected records must arrive
- Freshness SLAs — maximum acceptable data age by pipeline
- Accuracy tolerances — acceptable error rates by data domain
- Pipeline uptime expectations — by criticality tier
These are data quality SLAs with clear ownership — measurable contracts, not aspirational guidelines.
Governance for Distributed Teams
Without explicit governance documentation, distributed teams create conflicting definitions, schema drift, and data lineage gaps. Document clearly:
- Data ownership — who owns each domain's schema and can approve changes
- Metadata management — who updates the data catalog, and when
- Change control — no schema changes without a defined approval process
Gartner forecasts that by 2027, 60% of organizations will fail to realize anticipated AI-use-case value because of incohesive data governance frameworks. For offshore teams without documented governance, this failure mode arrives much faster.
Security and Compliance for Sensitive Data
Governance documentation sets the rules — security frameworks enforce them. For PE-backed healthcare and financial services clients, compliance requirements are non-negotiable and must be structured into the offshore engagement from day one:
- HIPAA: Offshore processing of ePHI requires a written Business Associate Agreement (BAA) and a risk analysis covering geographic exposure. Offshore engineers handling ePHI carry the same liability as onshore business associates.
- SOC 2: Offshore teams within SOC 2 scope operate as subservice organizations under AICPA CC9.2, requiring formal vendor risk assessment and management.
- Access controls: Role-based access by data sensitivity level, data masking in all non-production environments, NDAs, and IP assignment clauses — standard, not optional.
Colab91 incorporates SOC 2 and ISO 27001 compliance frameworks into its GCC and ODC setup engagements, with HIPAA compliance layered in for healthcare clients.
Documentation as Risk Management
For offshore data engineering teams, documentation is the primary defense against knowledge loss — not a courtesy, but an operational requirement.
Require, at minimum:
- Architecture Decision Records (ADRs) for significant pipeline design choices
- Schema documentation for every table or model the offshore team builds
- Runbooks for common failure scenarios, tied to specific pipelines
When an engineer leaves — and SHRM estimates replacing a technical employee costs 50–200% of annual salary — undocumented pipelines become liabilities. Documentation is how institutional knowledge survives turnover.
Measuring Offshore Data Engineering Team Performance
Track the Right KPIs
Generic software metrics don't surface data engineering performance. Track these instead:
- Pipeline SLA adherence — are pipelines delivering data within defined freshness windows?
- Data quality incident rate — incidents per pipeline or per data model per quarter
- Mean time to detect (MTTD) — how quickly does the team identify a data quality issue?
- Mean time to resolve (MTTR) — how quickly is it fixed once detected?
- Documentation contribution rate — is the offshore team building a documented, maintainable system or a black box?

Team Health Metrics That Predict Long-Term Success
- Engineer retention rate is the most underrated data engineering metric — when engineers leave, pipeline context and schema knowledge walk out with them
- Time to first independent pipeline deployment measures onboarding quality more honestly than any self-reported ramp timeline
- Escalation frequency reveals whether autonomy has actually been established — or whether offshore engineers are still routing routine decisions through onshore leads
Vanity Metrics to Avoid
Once you have the right metrics in place, it's worth identifying what to stop tracking. The following create perverse incentives:
- Lines of SQL written (incentivizes bloat)
- Number of pipeline commits (incentivizes activity over impact)
- Hours logged (incentivizes time-wasting)
The most honest measure of offshore data engineering performance isn't any single KPI — it's whether analysts are trusting and actively using the data the team produces. Build your metric system to surface that signal, not to obscure it.
Frequently Asked Questions
What are the biggest challenges of managing an offshore data engineering team?
The most consequential challenges are silent pipeline failures that go undetected across time zones, context gaps that drive incorrect schema or pipeline decisions, and governance standards that generic offshore guides skip entirely. Unlike typical software delivery, data engineering runs continuously — so each of these has compounding downstream impact.
How do you maintain data quality standards with an offshore data engineering team?
Define quality thresholds as written data quality SLAs before any work begins, enforce automated quality checks in the CI/CD pipeline so standards are tested at merge time, and assign clear ownership for quality monitoring so offshore engineers are accountable — not just responsive when issues are escalated.
What tools are most important for managing an offshore data engineering team?
Project management (Jira or Linear), communication (Slack with defined channel conventions), documentation (Confluence or Notion), code versioning (GitHub or GitLab), data quality tools (dbt, Great Expectations), and async video for context-rich walkthroughs (Loom). Consistent conventions across these tools matter more than which specific tool you choose.
How do you protect sensitive data when working with offshore data engineers?
Role-based access controls by data sensitivity, data masking in all non-production environments, contractual protections (NDAs, IP assignment), and compliance with applicable regulations. For healthcare clients, a Business Associate Agreement is required; for financial services, SOC 2 subservice organization controls apply.
Is India a good location for building an offshore data engineering team?
India leads Kearney's 2023 Global Services Location Index and holds the second-largest AI/ML/Big Data Analytics talent pool globally. The cost structure, talent depth, and manageable time zone overlap with US teams make it the most practical offshore destination for data engineering. Location sets the ceiling. Management discipline determines the actual outcome.
How long does it take for an offshore data engineering team to reach full productivity?
With structured onboarding: 30 days for ecosystem familiarization and low-risk tasks, 60 days for independent pipeline work, 90 days for domain ownership including incident response. Without structured onboarding and documentation, this timeline stretches to 5–6 months, with higher error rates throughout.